Программа AI AlphaStar компании DeepMind выступила против лучших профессиональных игроков StarCraft и выиграла.
После нескольких месяцев обучения, искусственный интеллект AlphaStar теперь может профессионально играть в StarCraft II и уверенно побеждать киберспортсменов. Освоение такой сложной игры является важным технологическим скачком для AI DeepMind.
Нейросеть обыграла профессионалов StarCraft II
В двух словах:
-
- AI AlphaStar победил двух профессиональных игроков StarCraft 2 из Team Liquid – Дарио Вюнш «TLO» и Гжегожа Коминц «MaNa».
- В обоих случаях AI выиграл 5:0, хотя Коминцу удалось одержать победу в одной дополнительной игре, сыгранной впоследствии.
- ИИ учился 14 дней, получая опыт, сопоставимый с 200 годами непрерывной игры.
Еще в 2016 году компания DeepMind объявила о партнерстве с создателями Starcraft Blizzard Entertainment, направленной на развитие искусственного интеллекта и машинного обучения. Теперь, спустя менее чем три года, британской исследовательской лаборатории есть что показать.
На протяжении десятилетий игры использовались для тестирования и оценки производительности систем искусственного интеллекта. По мере того как ИИ развивался, исследователи искали более сложные игры, которые отражают различные элементы интеллекта, необходимые для решения научных и реальных задач. В последние годы StarCraft считается одной из самых сложных и популярных киберспортивных игр, которая и стала “полигоном” для тестирования и обучения ИИ.
Кратко об игре StarCraft

В игре существует три игровые «расы»: зерги, протоссы и терраны. Каждая состоит из разных юнитов с различными способностями. Главная задача юнитов — добыча ресурсов и атака противника.
Основной акцент в игре делается на добыче ресурсов и многочисленных сражениях. Добывая ресурсы, игрок получает средства для строительства зданий, которые могут производить юнитов и улучшать их. Основной целью игрока является уничтожение всех зданий противника.
Для успешной игры необходимо сбалансировать краткосрочные и долгосрочные цели и адаптироваться к неожиданным ситуациям, что является большой проблемой для систем, которые не способны быть гибкими в своих решениях. Данная задача требует прорывов в нескольких направлениях исследования ИИ, включая:
- Теорию игр: StarCraft – это игра, в которой не существует единой лучшей стратегии. Таким образом, ИИ должен постоянно исследовать и расширять границы стратегических знаний.
- Недостаток информации: в отличие от таких игр как шахматы или го, в которых игроки видят все, в игре StarCraft существует “туман войны” – важная информация скрыта от игрока.
- Долгосрочное планирование: действия, предпринятые в начале игры, могут не окупиться в течение длительного времени, что требует особого анализа и прогнозирования.
- В режиме реального времени: в отличие от традиционных настольных игр, в которых игроки чередуют ходы между последующими ходами, игроки StarCraft должны выполнять действия непрерывно в течение всего времени.
- Пространство действия: сотни различных юнитов и зданий должны контролироваться одновременно, в режиме реального времени, что приводит к комбинаторному пространству возможностей. Кроме того, действия являются иерархическими, они могут быть изменены и дополнены.
Из-за этих и других сложностей StarCraft превратился в «грандиозную задачу» для исследователей ИИ.
Как обучался AI AlphaStar
Поведение AlphaStar генерируется нейронной сетью глубокого обучения, которая через интерфейс получает сырые данные (список юнитов и их свойств) и выдает последовательность инструкций для действий в игре.
Изначально нейронная сеть тренировалась с помощью метода обучения с учителем на основе игровых реплеев, где и научилась имитировать основные микро- и макро-стратегии, используемые игроками в турнирах.
Также AlphaStar использует новый мультиагентный алгоритм обучения. На каждой итерации новые агенты разветвляются, а первоначальные замораживаются. Вероятности встречи с другими оппонентами и параметры определяют цели обучения для каждого агента, что повышает сложность. Параметры агента обновляются методом обучения с подкреплением, основываясь на исходе игры против соперников.
Затем эти результаты используются для начала мультиагентного процесса обучения с подкреплением. Специально для этого была создана лига, где агенты-оппоненты играют против друг друга подобно тому, как люди получают опыт, играя в турниры.

{kind=link}
Такая форма обучения позволяет создать непрерывный процесс исследования огромного стратегического пространства геймплея StarCraft’а и убедиться, что агенты в силах противостоять наиболее сложным стратегиям, не забывая при этом старый опыт.
По мере развития лиги и создания новых агентов появлялись стратегии, которые позволяли победить предыдущие. В то время как некоторые агенты занимались оттачиванием своей стратегии, другие создавали абсолютно новые, включающие в себя необычные билд-ордеры, состав юнитов и макро-менеджмент.
К примеру, на ранней стадии процветали «чизы» — быстрые раши с помощью фотонных (Photon Cannons) пушек или темных тамплиеров (Dark Templars), но по мере продвижения процесса обучения рискованные стратегии были отложены. Этот процесс очень похож на то, как обычные игроки находят новые решения, позволяющие побеждать старые популярные и многолетние игровые стратегии StarCraft-а.
В процессе развития становилось заметно, как меняется состав юнитов, которым пользуются агенты.

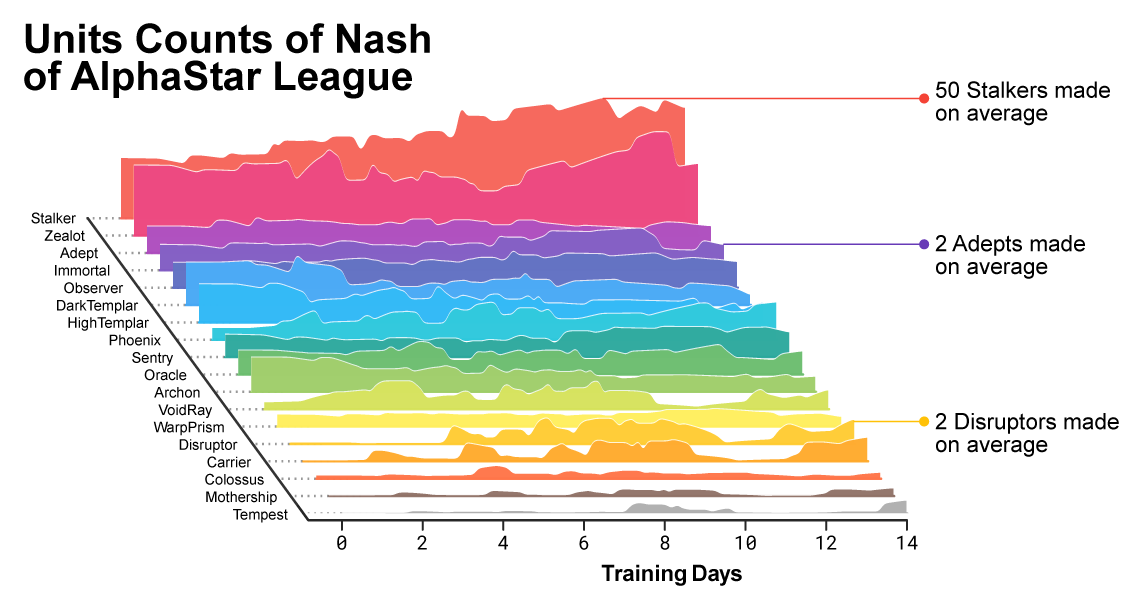{kind=link}
Для обучения AlphaStar была создана масштабируемая распределенная система на базе Google TPU 3, которая обеспечивала процесс параллельного обучения целой популяции агентов с тысячами запущенных копий StarCraft II. Полное техническое описание сейчас готовится к публикации в рецензируемом научном журнале.
Главный вызов
Разработчики из команды Google в DeepMind сообщили, что их «агент» AI AlphaStar смог победить двух профессиональных игроков StarCraft 2: Дарио «TLO» Вюнша и Гжегожа «MaNa» Коминца из Team Liquid в турнире из пяти матчей со счетом 5:0. Условия и правила игры были на уровне профессиональных матчей, за исключением того, что можно было играть только за протоссов. Все игры проводились на карте Catalyst LE, в которой места вражеских баз были размечены заранее.
Следует отметить, что хотя TLO является профессиональным игроком, занявшим 44-е место в мире, он не специализируется на расе протоссов, что дало некоторое преимущество AI AlphaStar в этих раундах, а MaNa занимает 13-е место в мире, играя за протоссов.
Первоначально ничто не указывало на такой результат – наблюдая за играми, в которые играет AlphaStar, Вюнш был абсолютно убежден, что он одолеет ИИ, даже несмотря на вышеупомянутое ограничение (протоссы – не его конек). Однако, когда он начал игру, ИИ использовал совершенно другую, нетрадиционную стратегию, которой он не смог противостоять.
Откуда взялся впечатляющий счет AlphaStar? Нейронная сеть поначалу изучала принципы StarCraft 2 на основе реплеев матчей, в которых участовали реальные игроки. Затем обучение ИИ вступило во второй этап, в котором были созданы другие агенты ИИ, соревнующиеся друг с другом. Обучение проводилось в течение 14 дней, каждый агент ИИ использовал 16 процессоров. Это позволило отдельным агентам получить опыт, в общей сложности, эквивалентный 200 годам непрерывной игры в StarCraft 2.
Наконец, наиболее эффективные из обнаруженных стратегий были выбраны и включены в один «агент», запущенный на одном графическом процессоре.
Как AlphaStar видит игру и действует
Визуализация AlphaStar во время поединка против MaNa демонстрирует игру от лица агента — исходные наблюдаемые данные, активность нейронной сети, некоторые из предполагаемых действий и требуемых координат, а также предполагаемый исход матча. Также показан вид игрока MaNa, но он, разумеется, недоступен для агента.

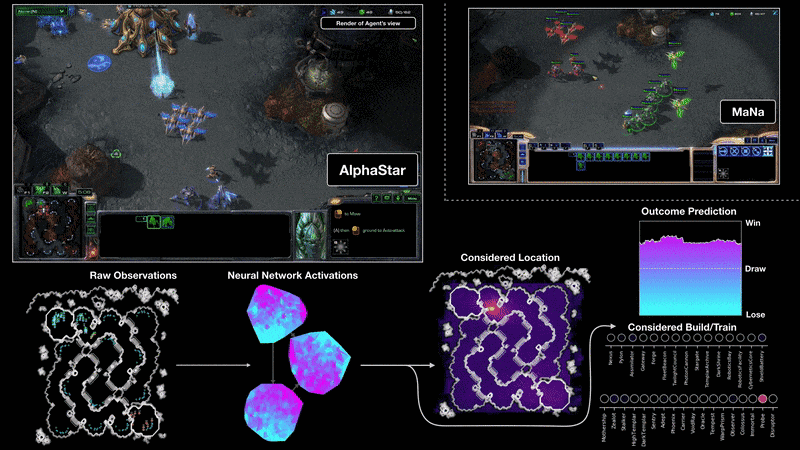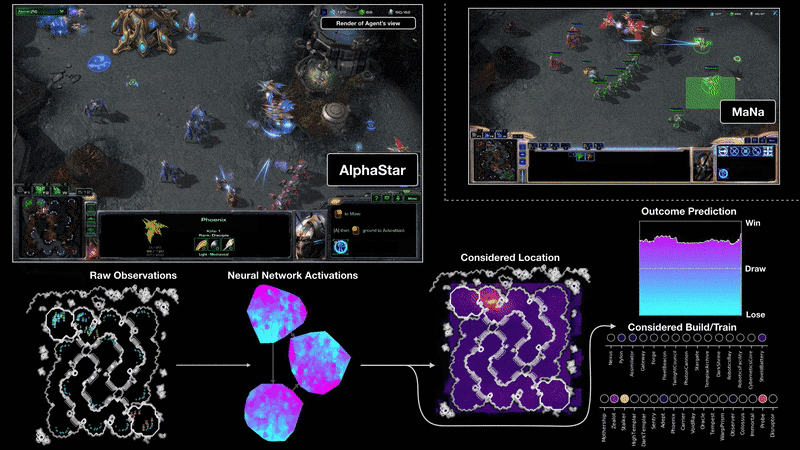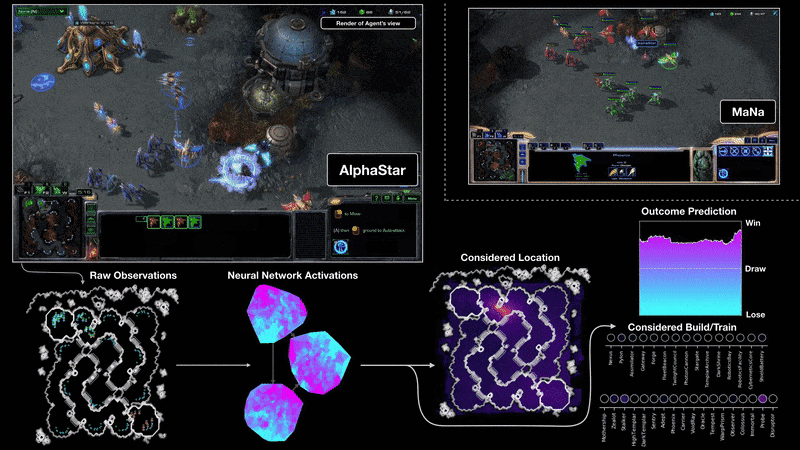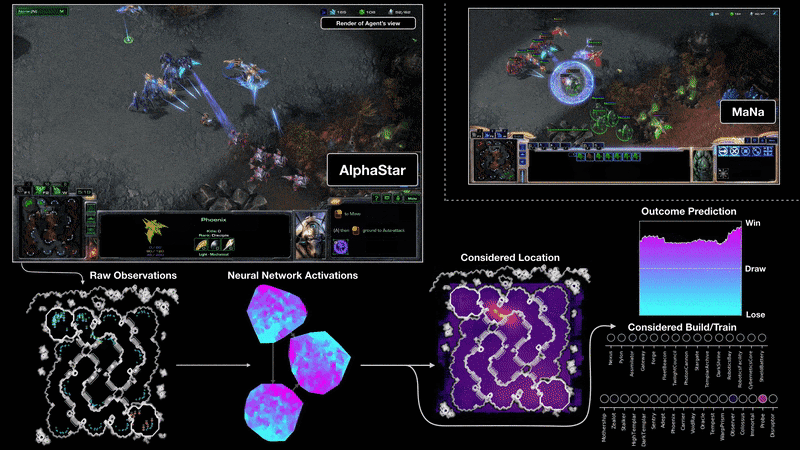{kind=link}
Профессиональные игроки, такие как TLO или MaNa, способны совершать сотни действий в минуту (APM). Однако это намного меньше, чем могут большинство существующих ботов, которые независимо контролируют каждого юнита и генерируют тысячи, если не десятки тысяч действий.
В играх против TLO и MaNa, AlphaStar держал APM в среднем на уровне 280, что меньше чем у профессиональных игроков, хотя его действия, при этом, могут быть более точными. Такой низкий APM объясняется, в частности, тем, что AlphaStar обучался на реплеях обычных игроков и пытался подражать манере человеческой игры. В дополнение к этому, AlphaStar реагирует с задержкой между наблюдением и действием в среднем около 350 мс. ИИ взаимодействовал с игровым движком через базовый интерфейс и мог видеть своих и вражеских юнитов напрямую, без необходимости двигать камеру. Игрокам же приходится управлять «экономикой внимания», чтобы постоянно решать, где сфокусировать камеру.
AI подвела самоуверенность
Люди все еще имеют существенное преимущество даже перед лучшим ИИ. MaNa разработал новую стратегию на основе предыдущих пяти матчей, и в последней одиночной игре, все же, победил AlphaStar.
Комментаторы заявили, что во время матчей с TLO, AlphaStar играл смелее, выполняя нелепые стратегии, которые обычно не встречаются в обычной человеческой игре, а во время игры с MaNa искусственный интеллект, похоже, утвердился в более привычном стиле игры, и проиграл. Вполне возможно, что ИИ не смог персонализировать опыт игры с конкретным игроком, сделать выводы, а затем разработать и применить новую стратегию в следующем матче.
Тем не менее, дикторы отметили, что AlphaStar во многих отношениях был поразительно похож на человека. Он проводил хитрые маневры, раннюю атаку, реагировал на засаду и хорошо ориентировался на местности. Кажется, что у человечества еще есть надежда, хотя следует признать, что наши шансы невелики.
- Купить майнинг оборудование: Какое выбрать?
- Биткоин: где купить? Обзор некоторых платформ для покупки криптовалюты
- Cryptonica — лучший информационный портал о криптовалюте
- Прогноз курса Ethereum: опасения регулирующих органов по поводу будущего ETH стремительно растет
- Обмен юсдт на российские рубли